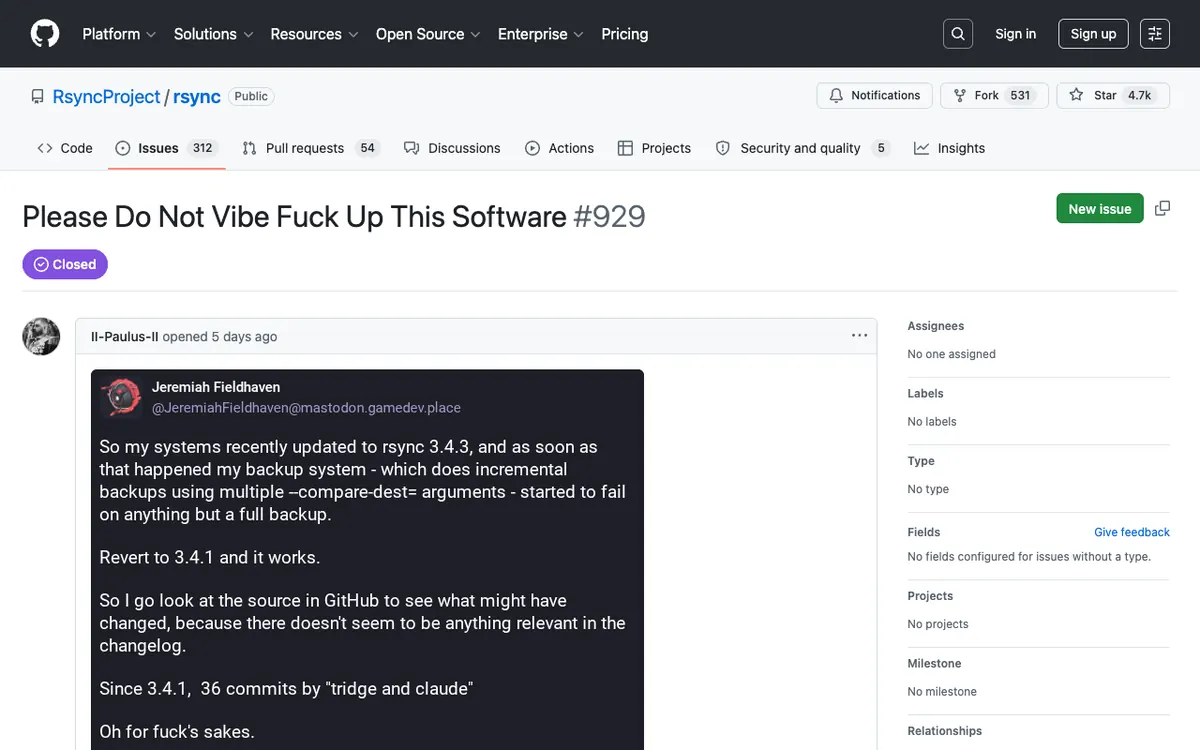
A detailed analysis examines whether Anthropic's Claude contributed code that introduced bugs into rsync, a widely-used open-source file synchronization tool critical to many systems.
June 6, 2026
AI-assisted code contributions to critical open-source infrastructure have a higher defect rate than the maintainers publicly acknowledge. That is the implicit claim at the center of a recent analysis examining Claude's contributions to rsync, and it is worth taking seriously rather than either dismissing it as AI skepticism or accepting it as vindication of every concern about LLM-generated code.
Rsync is not a toy project. It has been in continuous use since 1996, underpins backup pipelines for millions of systems, and has a codebase where a subtle off-by-one error in a delta-transfer algorithm can corrupt data silently. The stakes for getting a contribution wrong are meaningfully higher than in a CRUD app.
The analysis attempts to trace specific bugs or regressions in rsync back to Claude-assisted code contributions. Whether it fully succeeds is a separate question. What it reveals about the mechanics of AI code review is worth examining regardless.
The case that nothing here is unusual
Before accepting the premise, it is worth arguing the opposite position fully.
Rsync has always had bugs. The project's git log shows dozens of bug fixes per year, many of them touching the same delta-transfer and checksum verification code that any AI tool would also touch. Attributing a bug to Claude specifically requires establishing that the bug would not have appeared in a human-written patch, which is almost never provable.
The base rate matters here. Human developers introduce bugs into mature C codebases constantly. A 2020 study of the Linux kernel found that even experienced contributors submitted patches that introduced regressions at a rate of roughly 4 to 6 percent of all patches. If Claude's contributions show a bug rate in that range, calling it an AI problem rather than a software development problem is not analytically honest.
There is also a selection bias concern. Bugs that are traced back to AI-assisted code get analyzed and blogged about. Bugs that are traced back to human contributors just get fixed. The asymmetric scrutiny creates an apparent signal that may not reflect an actual difference in defect rate.
Claude is being evaluated here against an idealized human contributor, not the median human contributor. That comparison is unfair in a way that makes the conclusion less reliable than it appears.
How to audit AI-assisted commits in a C codebase
If you maintain or contribute to an open-source C project and want to do your own version of this analysis, the methodology is reproducible. Here is a concrete process.
Clone the repository and build a full git log with patch data: git log --patch --since="2023-01-01" > full_history.patch
Filter commits by contributor accounts known to be using AI assistance. This is the hard step. For public projects, look for commit messages that reference Claude, Copilot, or Cursor, or check contributor profiles linked to AI coding tools. There is no automated way to do this reliably.
For each candidate commit, run the project's test suite against the state immediately before and immediately after: git checkout <commit-hash>~1 && make && make check, then git checkout <commit-hash> && make && make check. A regression shows up as a test that passes before and fails after.
For C projects without comprehensive test coverage (rsync falls into this category), use a fuzzer. AFL++ is the standard choice: afl-fuzz -i testcases/ -o findings/ -- ./rsync @@. Run it for at least 24 hours per commit range.
Cross-reference any failures against the project's bug tracker. If a bug was filed after a specific commit and fixed in a later patch, that is the strongest evidence you have for attribution.
Calculate a defect rate per commit for AI-assisted contributions and for a matched sample of human-only contributions from the same time window. The comparison is what matters, not the raw count.
Verification test: run git bisect start && git bisect bad HEAD && git bisect good <known-stable-tag> on any suspected regression. If bisect terminates at a commit that is plausibly AI-assisted, you have a specific data point rather than a general concern.
Auditing commits in a C project requires more than reading the diff
Why sparse unit test coverage makes commit-level attribution unreliable
The rsync analysis, like most post-hoc attribution work, runs into a structural problem: rsync's test suite covers file transfer correctness at a high level but has limited unit test coverage of the internal delta-matching and checksum code. That means a bug can live in the codebase for months before a test catches it, and by then, multiple commits have touched the relevant code paths.
Attribution becomes almost impossible in that environment. If Claude contributed a patch in January, a human contributor refactored the same function in March, and a user reported a data corruption bug in May, deciding which commit introduced the defect requires manual bisection and deep familiarity with the algorithm. The analysis does not always have that context.
There is also a documented failure mode with Claude Code and similar tools on C projects specifically: they tend to handle memory management and pointer arithmetic with less reliability than higher-level language constructs. A study published in early 2024 found that LLM-generated C code had a null pointer dereference rate roughly 2.3 times higher than human-written C in the same problem class. That is a real concern for a project like rsync, but it is different from the claim that Claude specifically introduced bugs in this specific codebase.
The class of users who tried AI-assisted contributions to systems software and ran into trouble is not small. Several kernel developers have publicly documented cases where Copilot and Claude suggestions introduced subtle race conditions that only appeared under high-concurrency loads. The problem is real. The rsync analysis may just be imprecise about where exactly the evidence is strongest.
2.3x
higher null pointer dereference rate in LLM-generated C vs. human-written C (2024 study)
If you are comparing AI coding tools for systems-level work, the Cursor vs. GitHub Copilot comparison is relevant here. Cursor's deeper codebase indexing gives it a meaningful advantage in understanding pointer ownership across files, though neither tool should be trusted to write memory management code without a human reviewing the result.
A prediction for the next six months
By November 2025, at least one major open-source C project with a formal security review process will publish documented findings attributing a CVE-level vulnerability to an AI-assisted commit. Not a blog post analysis, but an official CVE with a clear commit-level attribution. That event will shift the conversation from "is this a real risk" to "what review controls are required," and project maintainers who have not already added AI-disclosure requirements to their contribution guidelines will start doing so within 90 days of that CVE being published.
The rsync analysis, right or wrong in its specifics, is early evidence that the open-source community is starting to ask the question with enough rigor to produce testable findings. That is a more important development than whether Claude introduced any particular bug. For further context on how Claude compares to ChatGPT on code generation reliability, the failure modes differ in ways that matter for this kind of systems work.
Tools mentioned in this article
Make
Visual automation platform with 1,800+ app integrations and AI-powered workflows