Anthropic Releases Claude Fable 5
Anthropic has unveiled Claude Fable 5, the latest iteration of its AI model with enhanced capabilities. The release includes a comprehensive system card detailing the model's features and safety considerations.
June 11, 2026

How to decide whether Fable 5 changes anything for your workflow
The decision is not whether Fable 5 is better than Fable 4. By most reported benchmarks it is. The decision is whether the improvements land in the areas where your current setup is actually failing.
If your primary use is long-context document analysis, the upgrade is worth testing immediately. Anthropic's Fable 5 release notes cite significant gains in multi-document reasoning and context retention. That is a specific, measurable claim you can verify against your own documents.
If you are running code generation through the API, test before committing. Code quality improvements between Claude generations have historically been uneven across languages. Python tends to improve consistently. Less common stacks are less predictable. Run your existing eval suite on Fable 5 before updating any production prompt configurations.
If you are using Claude for short-form copy or content tasks, the upgrade is unlikely to matter much. The gap between Fable 4 and Fable 5 on short outputs will be harder to notice than the benchmark tables suggest. You are already in a regime where both models are good enough.
If you are running a cost-sensitive high-volume workflow, check the token pricing before anything else. Model upgrades inside the Claude family often come with a price adjustment. A 15% capability improvement paired with a 20% cost increase is not an obvious win for production pipelines.
The short version: test if context handling or complex reasoning is a bottleneck for you. Skip the upgrade cycle if you are doing tasks where Fable 4 was already not the weak link.
What the model name signals about Anthropic's release strategy
Anthropic has been running two parallel naming conventions for a while now. The numbered generations (Opus, Sonnet, Haiku) describe capability tiers within a release. The named lines like Fable and Mythos describe something closer to specialization direction.
The analogy that helps here is think of it like a car manufacturer that makes the same platform in a sedan and a wagon. Same engine generation, different body configuration for different use cases. Fable 5 and Mythos 5 share an underlying model generation but are tuned toward different output profiles. Fable tends toward narrative coherence and longer structured responses. Mythos tends toward factual precision and citation-heavy tasks.
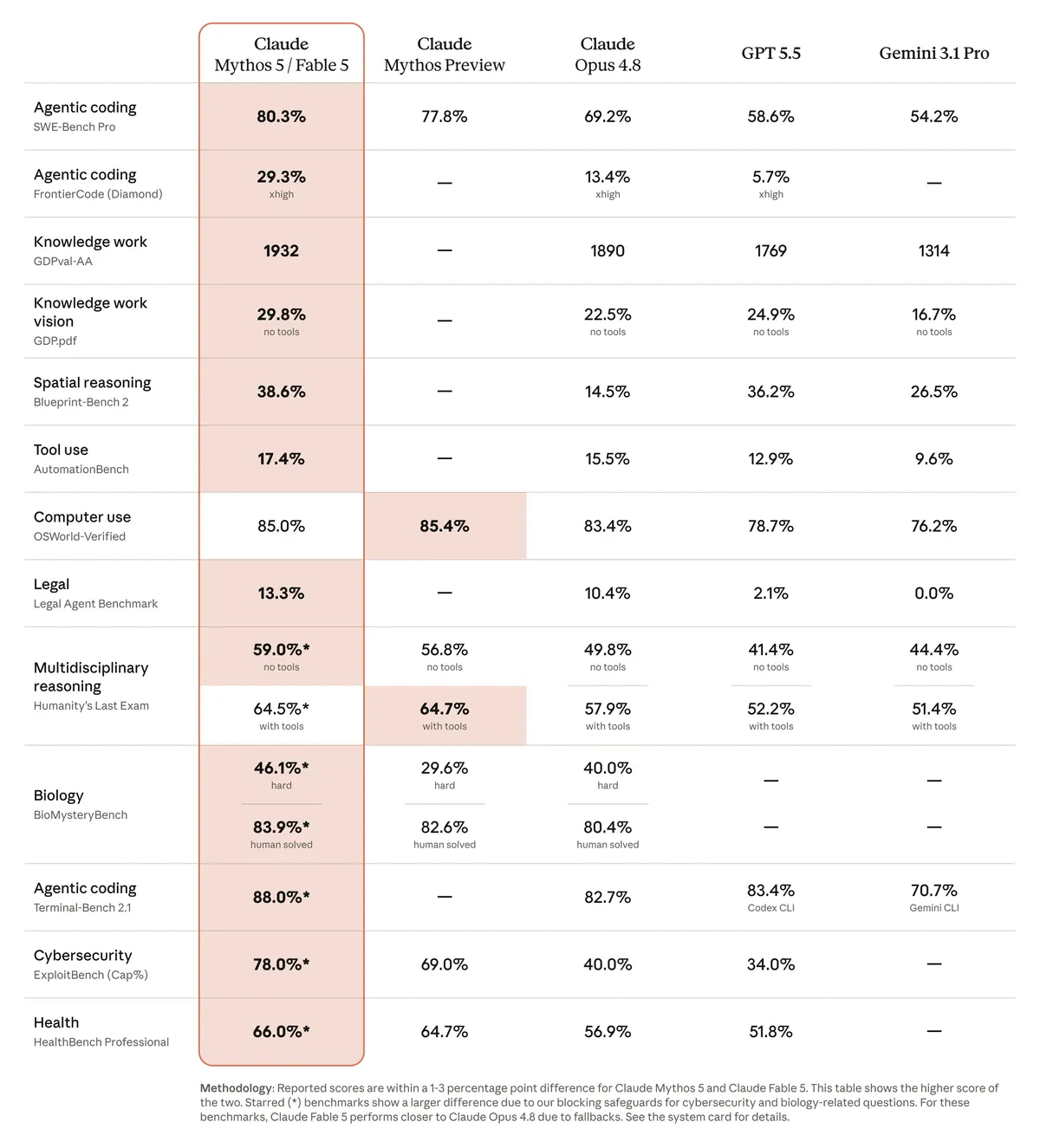
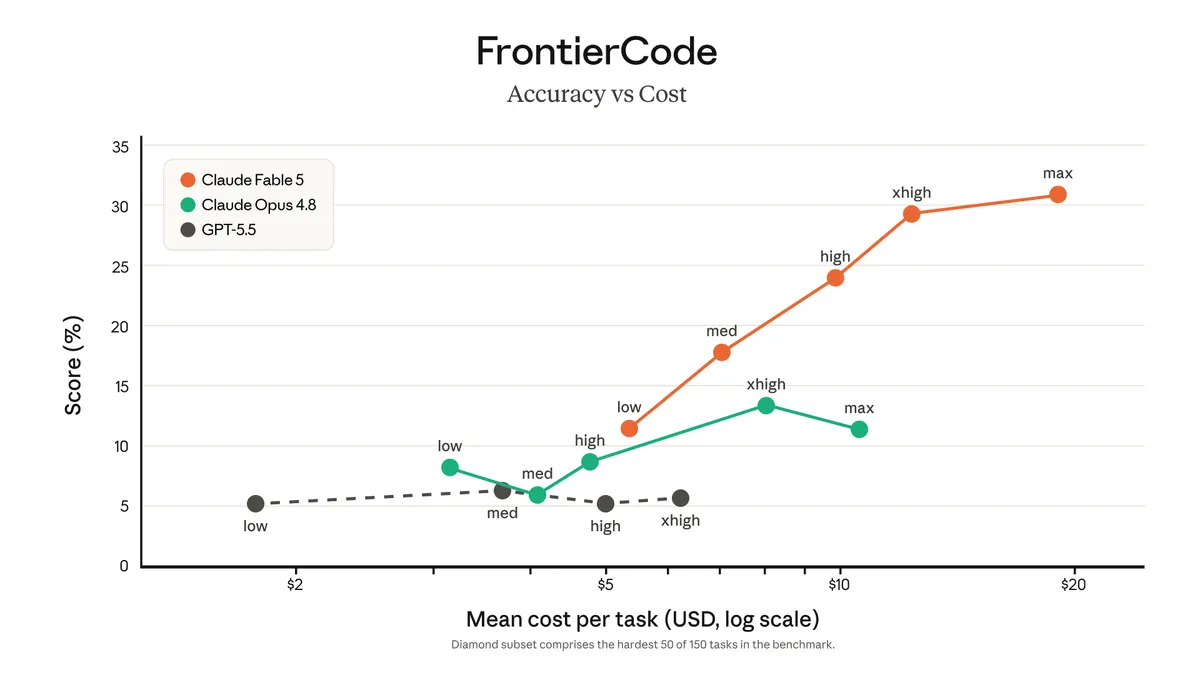
This matters because when you see a benchmark comparison between Fable 5 and, say, ChatGPT or Gemini, the benchmark is measuring one configuration of one model in one task regime. The score does not transfer cleanly to your use case unless your use case matches the benchmark task closely. Long-form creative writing scores will not predict code review performance. Retrieval accuracy on curated datasets will not predict behavior on messy internal documents.
The practical implication: when you see Fable 5 cited against Claude vs ChatGPT comparisons, check which version of each model the comparison used and what tasks it ran. Most published comparisons at launch are favorable to the new release because they test the tasks the new model was optimized for.
The number that defines this generation's ceiling
200k
token context window, consistent across Fable 5 and Mythos 5
The context window is the number worth holding onto here. 200,000 tokens is roughly 150,000 words, which is enough to load a full legal contract, all related correspondence, and supporting documentation into a single prompt without truncation.
If that number were half as large, say 100k, a meaningful portion of enterprise document tasks would require chunking strategies, which introduces retrieval error and requires engineering time to maintain. At 200k, many of those tasks become single-call operations. The workflow simplification is real.
If it were twice as large at 400k, the gains would start to hit diminishing returns for most practical tasks. There are real 400k-token use cases, wholesale ingestion of large codebases being the clearest example, but the jump from 200k to 400k matters to a narrower slice of users than the jump from 100k to 200k.
The related question is what happens to accuracy across that window. Context windows can be technically large but practically limited if the model starts losing track of content from the early part of a long input. The system card published alongside the release includes evaluation data on this, and it is worth reading before designing any workflow that depends on reliable retrieval from the second half of a 200k input.
For teams already using Claude Code for large repository tasks, the 200k window is the most practically significant spec in this release. Whether the model uses it reliably is the next question, and that one you will need to test yourself.
Before you ship anything using Fable 5
- Confirm the token pricing for Fable 5 against the tier you currently use and calculate the cost delta for your actual monthly volume.
- Run your existing benchmark or eval suite on Fable 5 outputs before updating any production prompt configurations.
- If you rely on long-context retrieval, test specifically whether the model maintains accuracy on content from the first 20% of a near-maximum-length input.
- Check whether the system card flags any new behavioral restrictions or refusal pattern changes that could affect your use case.
- If you are comparing Fable 5 against another model, verify that the comparison uses the same task type your workflow actually requires, not benchmark categories that sound adjacent.
- If you are using a routing setup with multiple model options, confirm which model identifier the API returns for Fable 5 to avoid unintended version changes.
Some links in this article are affiliate links. Learn more.