ai-codeai-trendshow-to
Achieve 3,000 tokens/sec LLM inference on consumer GPUs
New optimization techniques enable real-time large language model inference on standard GPUs, reaching 3,000 tokens per second throughput. A technical deep-dive into performance improvements for consumer-grade hardware.
June 2, 2026
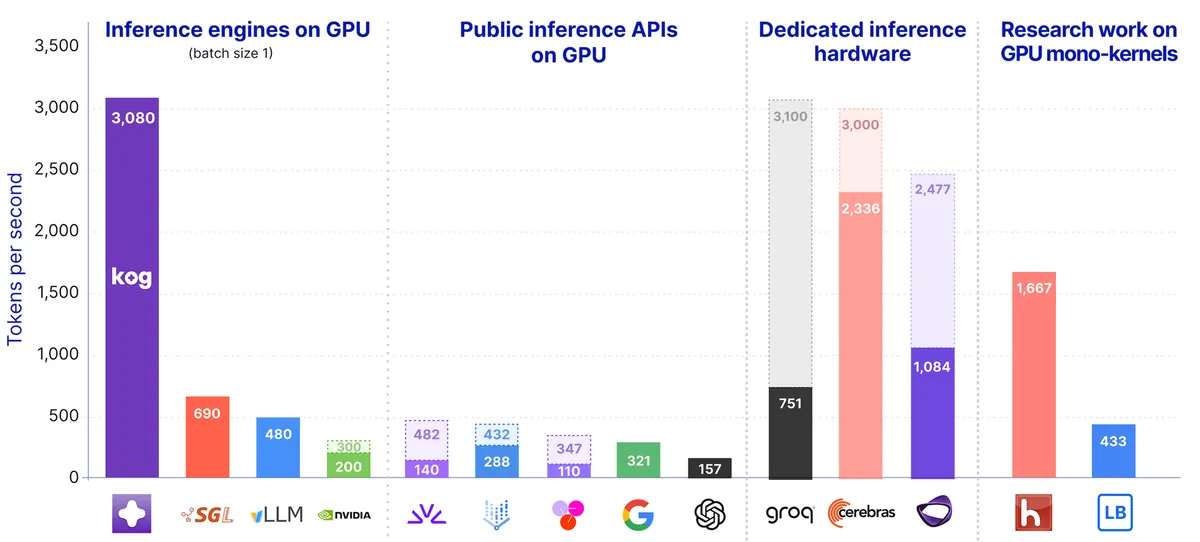
Eighteen months ago, getting 500 tokens per second out of a consumer GPU on a serious model required careful quantization, aggressive batching, and a tolerance for output quality degradation that made the whole exercise feel like a compromise. The Kog.ai team is now reporting 3,000 tokens per second per request on standard GPUs, which is not a modest improvement on prior work. That number changes the conversation about where LLM inference actually belongs.
The per-request distinction in that last row is important. vLLM's throughput numbers are aggregate: the system is fast because it is handling many requests simultaneously on expensive hardware. A single user's request is not necessarily getting 2,000 tokens/s. The Kog.ai claim is 3,000 tokens/s on a single request, on hardware that does not require a cloud contract.
For a solo developer running a coding assistant locally, the Kog.ai approach is the one to watch. For a team already invested in cloud inference at scale, the switching cost argument does not hold yet.
For comparison, GPT-4o mini is currently priced at $0.00015 per 1k input tokens and $0.0006 per 1k output tokens. The self-hosted math only wins at very high sustained utilization, and it requires you to believe the hardware cost is the only cost.
One test worth running this week: Pull up your current inference setup, whether it is a hosted API or a local Ollama instance, and measure your actual time-to-first-token and tokens-per-second on the specific model and prompt length you use most. Use a stopwatch if you have to. Engineers on many projects optimize for the wrong metric because they have never measured the right one. Once you have that baseline number, the Kog.ai claim and every competing claim becomes much easier to evaluate. You will also know whether your current bottleneck is generation speed at all, or whether it is something upstream like context retrieval, where posts like running Gemma 4 locally and reducing inference costs may be more immediately useful.
Three paths to fast local inference: how the options stack up
The 3k tokens/s result sits in a landscape with a few established approaches. Here is how the main options compare on the criteria that matter for production or near-production use.| Approach | Typical throughput (tokens/s) | Hardware requirement | Setup time | Output quality tradeoff | Batching model |
|---|---|---|---|---|---|
| llama.cpp (aggressive Q4 quant) | 80-200 on CPU, 400-800 on consumer GPU | Any modern GPU, 8GB+ VRAM | 30 minutes | Noticeable at Q4 vs FP16 on reasoning tasks | Single request |
| vLLM (cloud A100/H100) | 2,000-5,000 (batched across users) | Data center GPU, 40-80GB VRAM | 2-4 hours, cloud infra required | Minimal, runs full-precision models | Continuous batching |
| Kog.ai approach (standard GPU) | 3,000 per single request | Consumer or workstation GPU | TBD, early stage | Not yet independently benchmarked | Per-request, not batched |
A short argument about whether this number is real
Skeptic: 3,000 tokens per second on a consumer GPU. What model? What precision? What prompt length? The headline is missing half the information needed to evaluate the claim. Builder: Fair. The post does not specify the exact GPU SKU in the headline, and that matters. A 4090 has 24GB VRAM and 1,008 GB/s memory bandwidth. An A10G has 24GB but roughly half the bandwidth. Those are not the same machine. Skeptic: And throughput at what latency to first token? Fast generation is useless if you wait 4 seconds before anything appears. Builder: True. Time to first token is the number that defines perceived responsiveness for interactive use. If the first token takes 2 seconds and then 3,000 tokens arrive instantly, that is still a bad user experience for chat. It might be fine for batch document processing. Skeptic: So the claim is real in a narrow technical sense but needs a lot of context before it changes anyone's architecture decision. Builder: Yes. But the narrow technical sense is new. Nobody was hitting these numbers on consumer hardware 18 months ago under any conditions.Hardware, setup, and ongoing costs of self-hosted inference at this speed
The cost of chasing this kind of performance is not just hardware. It is worth working through each layer. Hardware cost: An RTX 4090 currently runs around $1,600-1,800 new. A workstation-grade GPU like the RTX 6000 Ada (48GB VRAM) is closer to $6,500. If the technique requires a specific VRAM floor to work on larger models, the $1,600 number may only apply to smaller quantized models where the quality tradeoff re-enters the picture. Setup friction: The Kog.ai implementation is not yet a packaged library with a pip install and a README. Early-stage inference research typically means compiling from source, resolving CUDA version conflicts, and spending time on configurations that break silently. Budget two to three days of engineering time before you have a stable baseline. Opportunity cost: Running your own inference means owning your own inference. Model updates, security patches, CUDA driver compatibility, and uptime are all your problem now. Cloud APIs like those powering Cursor or Claude Code handle that invisibly. The value of that invisibility is real and goes uncounted in "look at this cost-per-token calculation" comparisons. Migration risk: If your application is currently built around OpenAI-compatible API endpoints, adopting a novel inference backend means integration work. Not insurmountable, but not free. vLLM and Ollama both expose OpenAI-compatible endpoints by default. A new entrant needs to match that or document the delta. Team buy-in: Self-hosted inference is an infrastructure commitment. One engineer can set it up; the whole team has to live with the on-call rotation when it breaks at 11pm. That cost is real and scales with team size.~$0.003
approximate cost per 1k tokens on self-hosted 4090, amortized over 2 years at 50% utilization
The mechanism behind the number
The standard story about LLM inference bottlenecks points to memory bandwidth, not compute. Generating tokens is sequential: each new token depends on all prior tokens, which means the GPU cannot fully parallelize the work the way it can during training. The attention mechanism requires reading the KV cache from memory on every decoding step. On a consumer GPU with 1,000 GB/s memory bandwidth, that ceiling is hit fast. What the Kog.ai approach appears to target is the KV cache read pattern specifically. The standard approach loads the full cache on every step. If you can restructure that access pattern, either through better tiling, smarter prefetching, or a modified attention kernel that reduces the memory footprint per step, you can get more tokens out before the bandwidth ceiling appears. This is related to work on Flash Attention and its successors, which reduce memory reads by restructuring the computation order. The reason this matters beyond the benchmark number is that consumer GPUs are not memory-bandwidth-constrained in the same ways as data center hardware. A 4090 has significantly higher compute-to-bandwidth ratio than an H100 in some configurations. That asymmetry means there is headroom that standard inference stacks were not designed to exploit. Kog.ai appears to have found some of that headroom. This is why the result is interesting independent of whether the exact number holds up under scrutiny. The implication is that inference optimization work designed around data center hardware has left efficiency on the table for consumer hardware, and consumer hardware is what local deployment, edge deployment, and cost-sensitive production environments actually run on. The broader consequence: if consumer GPUs can sustain 3k tokens/s per request, the architecture decisions for applications like real-time coding assistants, voice interfaces, and document analysis change. You do not need to stream partial responses and hide latency with spinners. You can complete a 500-token response in under 200 milliseconds. That is fast enough to feel synchronous to a user. The user experience implications of synchronous-feeling AI responses are different from streaming responses in ways that product designers have not fully worked through yet, partly because it has not been technically feasible until now.One test worth running this week: Pull up your current inference setup, whether it is a hosted API or a local Ollama instance, and measure your actual time-to-first-token and tokens-per-second on the specific model and prompt length you use most. Use a stopwatch if you have to. Engineers on many projects optimize for the wrong metric because they have never measured the right one. Once you have that baseline number, the Kog.ai claim and every competing claim becomes much easier to evaluate. You will also know whether your current bottleneck is generation speed at all, or whether it is something upstream like context retrieval, where posts like running Gemma 4 locally and reducing inference costs may be more immediately useful.
Some links in this article are affiliate links. Learn more.