Qwen3.6 vs Claude Opus: Open-Source Gains Ground
Alibaba's Qwen3.6 outperformed Claude on a visual task, signaling how open-source models are closing the gap on specific capabilities while remaining dramatically cheaper to operate.
April 17, 2026
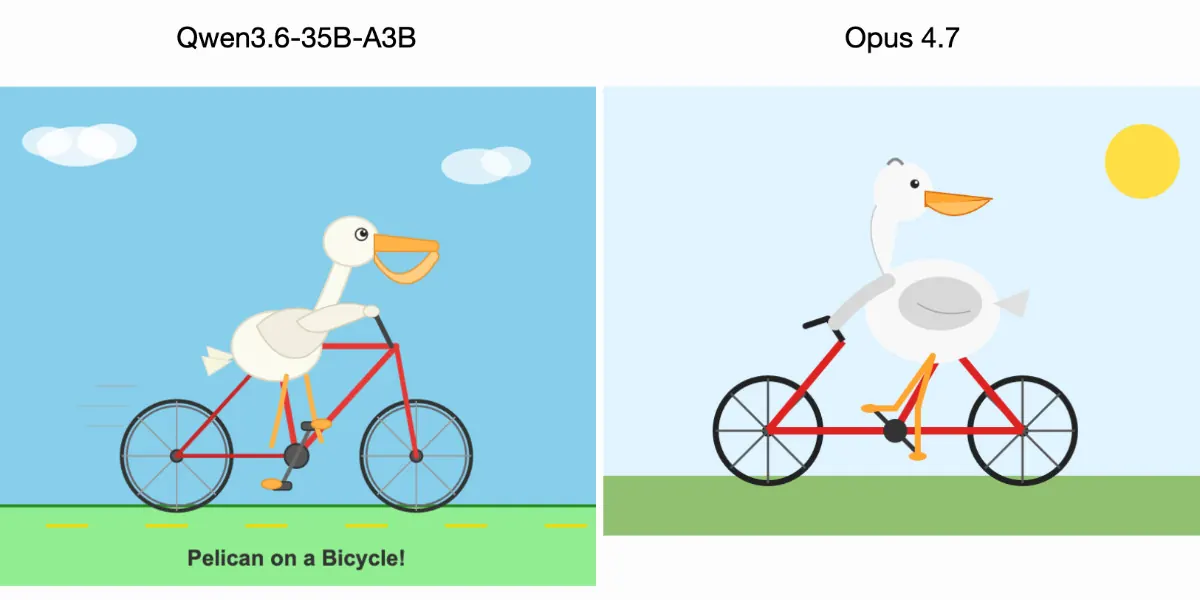
Qwen3.6-35B drew a more recognizable pelican in SVG than Claude Opus 4.7. That single benchmark result - narrow, specific, and easy to dismiss - has been making the rounds because it points at something real. Open-source models are closing the capability gap on structured tasks faster than the average developer has adjusted their tooling choices to reflect.
The pelican test is not the story. The trajectory is.
TL;DR
Qwen3.6 outperforming Claude Opus on a visual-spatial task is a real data point, not an anomaly. Open-source models now match or exceed frontier models on structured, constraint-bound tasks. For high-volume workloads where the task has clear success criteria, the economics of local inference are hard to argue against.
What the architecture actually does
Qwen3.6-35B uses a mixture-of-experts design. Thirty-five billion parameters total, but only 3 billion activate during any given inference pass. A gating network routes each token to the relevant specialized subnetwork, then routes it out again. The result: you get knowledge encoded at 35B scale while paying the compute price of a 3B model.
The memory footprint difference is concrete. A dense 35B model in FP16 precision needs roughly 70GB of VRAM. Qwen3.6, with 3B parameters active at once, fits in around 6GB. That puts capable inference on hardware developers already own. An RTX 4090. A Mac with 24GB unified memory. A mid-tier cloud instance rather than an enterprise GPU cluster.
Token generation speed scales accordingly. At 3B active parameters you get fast output, not the slow grinding that made early local model experiments feel painful. This is the inflection point: local inference that's fast enough to feel like a tool rather than a wait.
3B
active parameters during inference despite 35B total - what makes Qwen3.6 viable on consumer hardware
Why the pelican result is specific and why that matters
Simon Willison's SVG pelican challenge asks models to write code that draws a recognizable pelican on a bicycle. The task requires spatial reasoning, code generation, and translating mental imagery into coordinate geometry. It's narrow. It's somewhat arbitrary. And Qwen3.6 did it better than Claude Opus 4.7.
One test proves nothing about general capability. But it proves something specific: on visual-spatial code generation, the open-source model is competitive. That matters because visual-spatial code generation is a real category of work. Reference image creation. SVG asset generation for product mockups. Diagram creation from descriptions. Developers are doing these tasks and currently paying frontier API rates for them.
The test also reveals where open-source has the most ground to make up. SVG generation has objective success criteria - the output is either valid code that renders something pelican-shaped or it isn't. Structured tasks with clear pass/fail conditions are where open-source models converge fastest. Tasks requiring sustained judgment across ambiguous inputs are where frontier models still maintain distance.
Where the gap is actually closing versus where it isn't
Closing fast: anything with a schema. SQL generation, JSON output, SVG, code that conforms to a type signature, API responses that need to match a spec. These tasks have a ground truth. The model either produces valid, correct output or it doesn't. Qwen3.6 performs well here, as do several other recent open-source releases.
Closing moderately: technical explanation and single-file code generation. Explaining a concept clearly, writing a standalone function with good error handling, debugging a stack trace with a clear root cause. Open-source models have improved substantially. The output is often 90% of what you'd get from Claude, which is sufficient for most purposes.
Still meaningful gap: long-context reasoning across hundreds of pages. Multi-constraint optimization where the model needs to weigh competing requirements stated pages apart. Ambiguous instructions where the right response is a clarifying question rather than a confident wrong answer. These are where Claude Opus earns the cost premium. The moat exists. It's just narrower than it was twelve months ago.
The economics of running this locally
Frontier API pricing for Claude runs approximately $3 per million input tokens at current rates. Qwen3.6 running on hardware you already own costs zero per token. For a development team processing 50 million tokens monthly on structured generation tasks - SQL queries, configuration files, simple code - that's $150 per month that goes to zero.
The crossover math depends on your hardware costs and usage volume, but the economics shift in favor of local inference more quickly than teams expect when they run the actual numbers. One-time hardware investment amortizes across months of usage. API costs recur every month forever.
The practical barrier isn't cost, it's setup friction. Downloading 7GB of model weights, configuring an inference server, connecting it to your tooling - this is an afternoon of work for someone comfortable with the terminal. It's not automatic. But it's not a month-long project either. Tools like Ollama have compressed the setup to a handful of commands.
ollama pull qwen3.6:35b
ollama run qwen3.6:35b "Generate SVG code for a pelican standing on a dock"What the right allocation looks like
The mistake is treating this as an either/or. It isn't. The developers getting the most value out of open-source gains are the ones who have mapped their workloads by task type and routed accordingly.
High-volume, structured generation: local Qwen3.6. You're paying API rates for tasks where the open-source model performs identically. That's waste with an easy fix.
Complex reasoning, large-context work, ambiguous instructions: frontier model. This is where the capability difference is real and the API cost is justified. Don't compromise quality on the tasks that actually need the best model.
The developers who haven't tested this are running everything through expensive APIs by default, subsidizing capabilities they never use. The pelican test is a prompt to audit that assumption, not a reason to abandon frontier models entirely.
Test Qwen3.6 against your actual high-volume workloads. Not the pelican. Not any benchmark. The real queries that consume most of your token budget. Measure output quality against your actual criteria. The answer for your specific situation might be 30% local, or 70%, or something else entirely. But you won't know until you run it.
Here's a falsifiable prediction worth tracking: by Q4 2026, at least one major open-source model release will match Claude Opus 4.7 on the standard long-context reasoning benchmarks. Not on every task - on the benchmarks. The benchmark gap that once justified large API premiums will close, and the differentiation will shift entirely to enterprise features, support, and safety guarantees.
Tools mentioned in this article
Some links in this article are affiliate links. Learn more.