Qwen 35B Beats Claude Opus on Image Generation Tasks
A real test shows local Qwen 3.6-35B matched or exceeded Claude Opus 4.7 on image generation, proving open-source models now handle specific tasks better than frontier AI at a fraction of the cost.
April 19, 2026
Picture this: you're starting a new project and need to decide in the next ten minutes whether to spin up a local model or reach for the cloud API. Your security team is asking questions about where code goes. Your API bill last month was $240. Your laptop has 32GB of RAM. The choice used to be obvious. Now it isn't.
That decision got meaningfully harder after a developer ran Qwen 3.6 35B locally and compared the output against Claude Opus 4.7 on a visual code generation task. The local model won. Not marginally. Recognizably better output on the specific thing being tested.
TL;DR
Local Qwen 3.6 35B beat Claude Opus on visual code generation in a direct comparison. For structured tasks with clear success criteria, open-source models running on consumer hardware now match or exceed frontier API performance - and cost nothing per token after hardware.
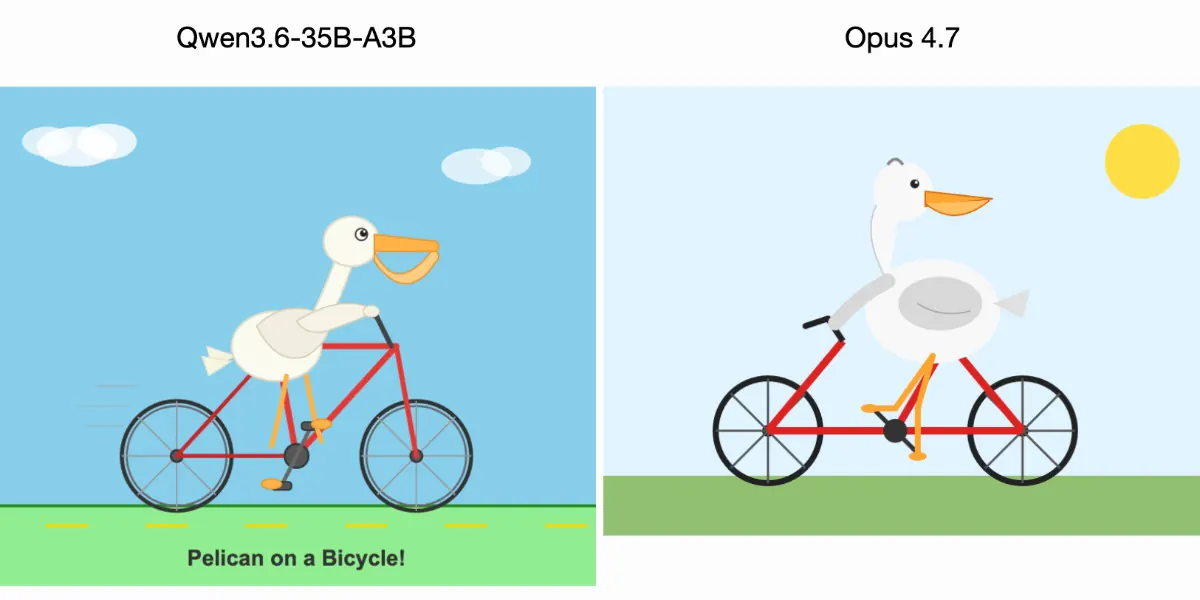
The test that shifted the calculus
Simon Willison gave both models the same prompt: generate SVG code that draws a recognizable pelican. Not a description of a pelican. Working SVG code. The task requires spatial reasoning, coordinate geometry, and the ability to translate a mental image into markup that renders correctly.
Qwen 3.6 35B produced a better pelican. Claude Opus 4.7's output was less recognizable as the bird it was supposed to be.
One test proves nothing about which model is better in a general sense. But it proves something specific and commercially relevant: on visual-spatial code generation, the open-source model running on local hardware is at minimum competitive. That task type - structured code generation from a visual or conceptual description - maps directly to real production workloads. Icon generation. UI component code from a design. Diagram markup. Developers are paying frontier API rates for exactly this kind of work right now.
What local inference actually costs to set up
The practical barrier to local inference has dropped substantially. Qwen 3.6 35B uses a mixture-of-experts architecture that activates only 3 billion parameters per inference pass despite having 35 billion total. The VRAM requirement drops from the 70GB a dense 35B model would need to around 6GB. A machine with 32GB of RAM and a recent GPU handles this comfortably.
Setup using Ollama is a handful of commands and about 7GB of download. The model serves locally as an OpenAI-compatible API, which means your existing tools - Cursor, Claude Code with a custom backend, any tool that accepts an API endpoint - can point at it without changes to your workflow.
The ongoing cost per token: zero. Your electricity bill will not change meaningfully. For a developer spending $100-200 monthly on API calls, the hardware amortizes in a few months.
$0
per token for local Qwen 3.6 inference after hardware - compared to ~$3 per million tokens for frontier API access
Where local models win, where they don't
The answer is task-specific. Local models have closed the gap fastest on tasks with clear, objective success criteria: valid JSON, correct SQL, SVG that renders, code that passes tests. If the output is either right or wrong, open-source models are now competitive.
Frontier models like Claude Opus still have real advantages on work that requires sustained judgment. Long documents where you need to synthesize contradictions between section 12 and section 87. Ambiguous specifications where the right response is a clarifying question rather than a confident bad answer. Architectural reasoning across a large codebase where subtle tradeoffs matter. These tasks are where the API cost buys you something real.
The practical implication is a tiered approach rather than a single vendor for everything.
| Task type | Local Qwen 3.6 | Frontier API | Recommendation |
|---|---|---|---|
| Structured code generation (SVG, SQL, JSON) | Competitive or better | No clear advantage | Local - save the tokens |
| Simple function generation from clear spec | Solid | Marginally better | Local for volume, API for complex cases |
| Long-context document reasoning | Noticeably weaker | Strong | Frontier API |
| Ambiguous instruction handling | Overconfident on bad paths | Better at asking for clarification | Frontier API |
| High-volume classification or tagging | Sufficient quality at zero per-token cost | Overkill | Local - clear economic win |
| Sensitive or proprietary code | Stays on your hardware | Leaves your network | Local for compliance-constrained work |
The privacy argument that doesn't get enough coverage
API pricing is the visible cost. Data exposure is the invisible one.
Every prompt you send to a cloud API leaves your network. Most enterprise terms-of-service include provisions about training data, logging, and retention that require legal review before you can use them on sensitive work. For teams handling client code, internal systems, or anything under NDA, getting AI assistance on cloud infrastructure requires a compliance process that slows everything down.
Local inference eliminates this entirely. Prompts never leave your machine. No logging. No retention policy to review. No data residency concern. For regulated industries, this isn't a secondary benefit - it's the primary one. The cost savings are just a bonus.
Compliance note
If your work involves proprietary code, client systems, or regulated data, local inference is not just cheaper - it may be the only option that doesn't require a legal review cycle before use.
How to actually test this for your workload
The pelican test tells you about one task type. Your API logs tell you about your actual workload. Pull them. Find your ten highest-volume prompt categories. Run those same prompts through local Qwen 3.6. Compare output quality against your actual success criteria, not a generic benchmark.
If Qwen's output is acceptable on 60% of those categories, you have a path to cutting your API spend significantly while maintaining quality where it matters. If it's only acceptable on 20%, the savings are smaller but the privacy benefit still stands for anything sensitive.
The developers who haven't run this test are making an assumption - that frontier models are always worth the premium - that the pelican result suggests is worth examining. One hour of honest testing with your own prompts will give you better data than any benchmark comparison.
Some links in this article are affiliate links. Learn more.